Poly-encoders, Facebook AI Research
논문 출처 https://arxiv.org/abs/1905.01969
Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
The use of deep pre-trained bidirectional transformers has led to remarkable progress in a number of applications (Devlin et al., 2018). For tasks that make pairwise comparisons between sequences, matching a given input with a corresponding label, two appr
arxiv.org
2018년 BERT가 나온 이후로 NLP 발전은 급속도로 진행되고 있으며, 이 후 버트의 변형체가 계속해서 등장하고 있다.
이 논문도 그 중 하나라고 볼 수 있을 듯?
문장의 쌍을 비교하는 task를 수행하기 위해서는 일반적으로 두 가지 접근방식이 있다.
- Bi-encoder: context와 candidate를 인코딩하는 인코더가 분리되어 있으며, candidate representation은 캐싱되기 때문에 inference가 빠르다는 장점이 있다. 정확도는 Cross-encoder에 비해 낮음
- Cross-encoder: 최종 representation을 얻기위해 context와 candidate를 결합하여 인코딩하기 때문에 더 풍부한 representation을 얻을 수 있지만, Bi-encoder처럼 candidate representation을 캐싱하지 않기 때문에 inference가 매우 느려서 서비스에 이용하기엔 적합하지 않을 수 있다. (근데 정확도가 높음)
2019년 4월에 게시된 이 논문(최종 수정 8월)은 Poly-encoder를 소개하고 있는데, 이는 위의 두 가지 유형의 인코더 장점을 결합하여 아키텍쳐를 이루고 있다.
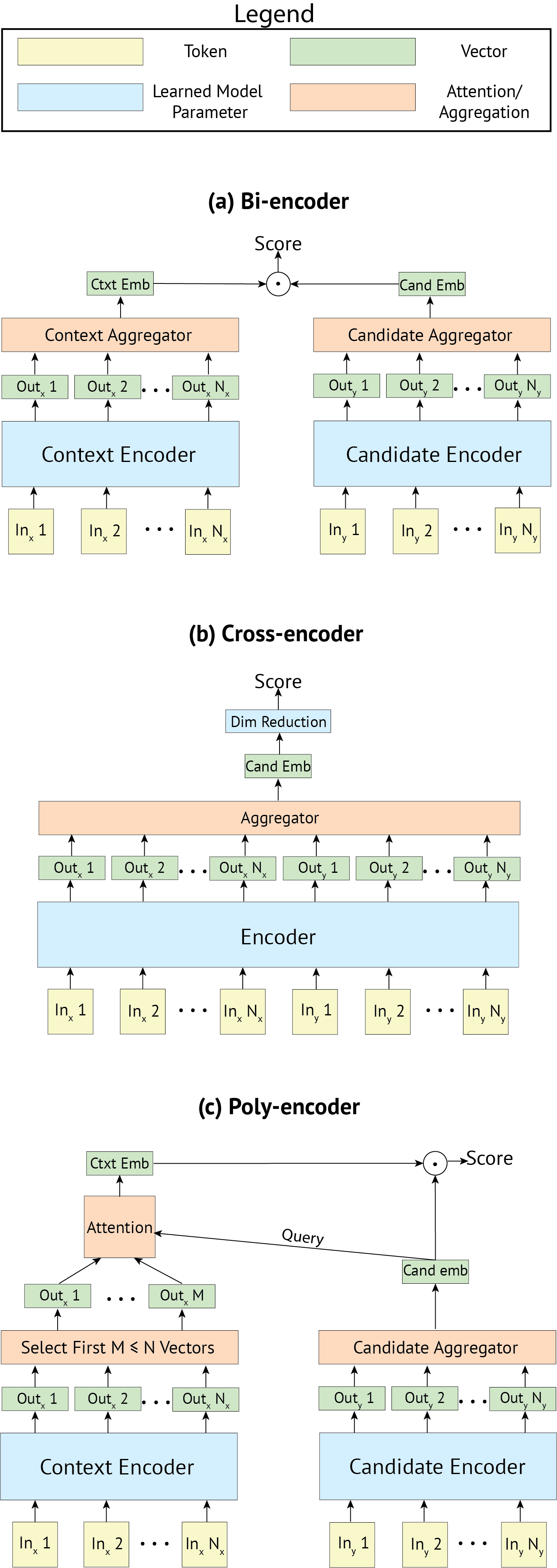
위의 구조도에서 보이는 것 처럼, Poly-encoder는 Bi-encoder 처럼 context와 candidate를 인코딩하는 인코더가 분리되어 있으며, 최종 score를 계산하기 위해서 candidate representation 을 캐싱해서 사용하고 이를 attention layer 를 적용하여 최종 임베딩을 추출한다.
이 논문에서 데이터셋은 ConvAI2, DSTC7, Ubuntu v2 세 종류를 가지고 실험을 했다.
실험 또한 기존 BERT와 비교하기 위해 BERT의 코퍼스와 하이퍼파라미터를 거의 그대로 이용해서 pretraining 한 모델과, task와 유사한 데이터를 pretraining에 이용하면 성능이 좋아질 것이라는 가정하에 코퍼스만 바꾸고 하이퍼파라미터는 그대로 이용한 모델, 그리고 기존 Bi-encoder 와 Cross-encoder 논문의 환경을 사용하여 이를 비교해보았다.


위의 실험 결과를 보면 task와 관련된 데이터셋을 사용하여 pretraining 한 모델이 전체적으로 성능이 더 좋은 것을 볼 수 있다.
그리고 모든 실험에서 Cross-encoder의 성능이 가장 좋지만, inference time을 비교한 것을 보면 매우 느린 것을 알 수 있다.
(실제로 서비스할 경우에 Cross-encoder를 사용하지 못하겠다는 판단이 설 정도...)
반면에 Poly-encoder의 경우 Cross-encoder 보다는 살짝 accuracy가 떨어지지만 속도를 보면 Bi-encoder에 뒤지지 않는다.
속도와 성능 모두 괜찮은 결과라고 생각된다.
실 서비스에 적용한다면 괜찮은 인코더인 것 같음!
구체적인 실험환경은 해당 논문에 잘 설명되어 있으니 참고.
코드는 요기서
https://parl.ai/projects/polyencoder/
Polyencoder
Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring Paper: https://arxiv.org/abs/1905.01969 Abstract The use of deep pre-trained bidirectional transformers has led to remarkable progress in anum
parl.ai